I called this series exploit alchemy because alchemy may lead metal into gold, but it is more about transmutation. so we are transmutating your neurons into neurons necessary for the void of vuln research. You come in reading code the way a developer does. you leave reading it the way an attacker does, seeing the gap between what software is supposed to do and what it actually does. That gap is where every vulnerability lives. the raw material is curiosity. What comes out the other end is someone who reads a crash and sees opportunity, that’s the alchemy.
About the series i want to start this by saying this took me a while to actually understand. Not because the concepts are impossibly hard, but because most of the material out there is either too surface-level (“send a long string and overwrite EIP!”) or assumes you already know what you’re doing. There wasn’t much in between. Although there are huge number of resources out there, I hope this would be a one of a kind because its end to end nature, so this is what i wish i had read when i was starting out. Most of the stuff here i got from the ost2 vulnerabilities class, big shoutout to xeno for making that. If you prefer video over reading or want to go deeper, seriously go check it out.
Also this series is for learning, ctfs, your own lab vm’s not for anything else. I dont think i need to say that but i will anyway.
I. What is Vulnerability Research actually
Most people describe vulnerability research as “finding bugs in software.” That’s technically correct but it does not tell you anything useful about what the work actually looks like day to day.
What you’re really doing is this: you take a piece of software, and you try to make it do something the developer didn’t intend. usually that means making it crash. Sometimes it means making it give you information it shouldn’t, sometimes and this is where exploit development starts: it means making it execute code you wrote. It is explained greatly in this presentation by Brandon Azad specially these slides and more, go check it out:
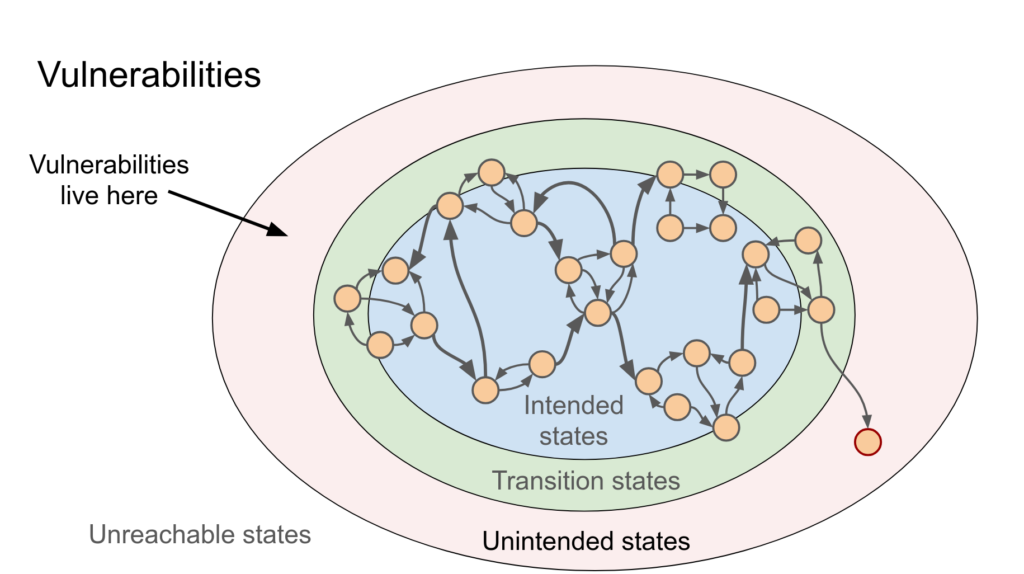
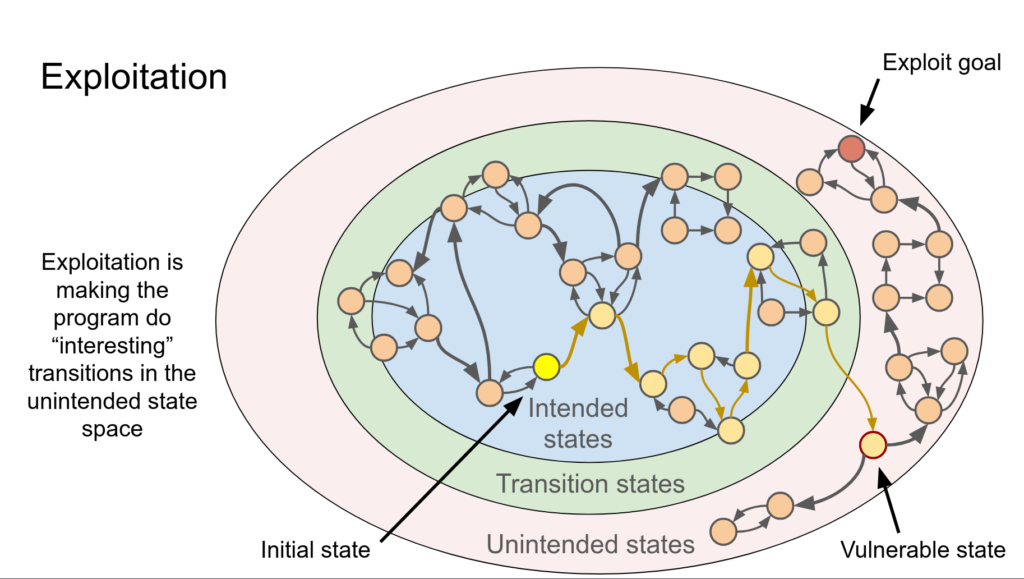
Thing that took me a while to accept is that this is fundamentally an engineering discipline. Its not hacking in the movie sense. its reading code (a lot of code), understanding systems at a pretty low level, and applying that understanding to find edge cases the original developer missed. The creativity is not in some clever trick, its in knowing what to look for and where to look for it. There are no miracle people, but there are miracle trajectories.
Bugs themselves are not exotic. The same bug classes keep showing up decade after decade: memory corruption, integer issues, type confusion, use-after-free, logic errors. What changes is where they appear and how hard the surrounding environment makes exploitation. the fundamentals are stable.
What you actually need to get good at this:
You need to be comfortable with C. not “i can write a hello world” but actually understanding what a pointer is, what happens when you do pointer arithmetic, why sizeof() does what it does. Most of the bugs we care about are in C and C++ codebases and you cant find something you do not understand.
You need to understand x86-64 assembly, not to write assembly from scratch, but to read it. When we’re looking at a crash in a debugger we are looking at assembly. When you are building a rop chain you are looking at assembly. You do not have to be fluent but you have to be able to read it without panicking.
You need to actually use a debugger. windbg on windows, gdb on linux. not just “set a breakpoint and step through” but being comfortable inspecting memory, reading the stack, modifying register values, setting conditional breakpoints. The debugger is where you spend most of your time. You can check out ost2 for intro to assembly too.
Everything else: the tools, the specific techniques, you pick up as you need them.
II. Exploit Dev vs finding bugs
I want to draw a distinction that most introductory material glosses over.
Finding a vulnerability and developing an exploit are different skills. they overlap, but they are not the same thing.
Finding the bug is about knowing what patterns are dangerous, reading code well enough to spot them, and having good tooling (fuzzers, static analyzers) to help at scale. Its more like code review with a specific threat model.
Exploit development is what happens after the crash. You have a program that faults when you send it a specific input. Now what? Turning that crash into reliable, controlled code execution is a completely separate engineering problem.
The gap between “this crashes” and “i have a shell” can be trivial or it can be weeks of work. It depends on the bug, the target, the mitigations in place, and how much control the bug actually gives you. Most crashes you’ll encounter in the real world do not immediately give you control of instruction pointer. You have to work for it and snatch victory from the jaws of defeat.
“reliable” is the word industry emphasizes. Anyone can get something working once. Exploit that works 1 in 100 tries is useless in practice. The work of exploit development is largely about understanding the system well enough to make something consistent across reboots, across slightly different memory states, across different versions of the target.
III. Stack: What lives in it
Enough of me yapping. This is where we get into the actual technical content.
Stack behaves as Stack Data Structure but not a Stack Data Structure!
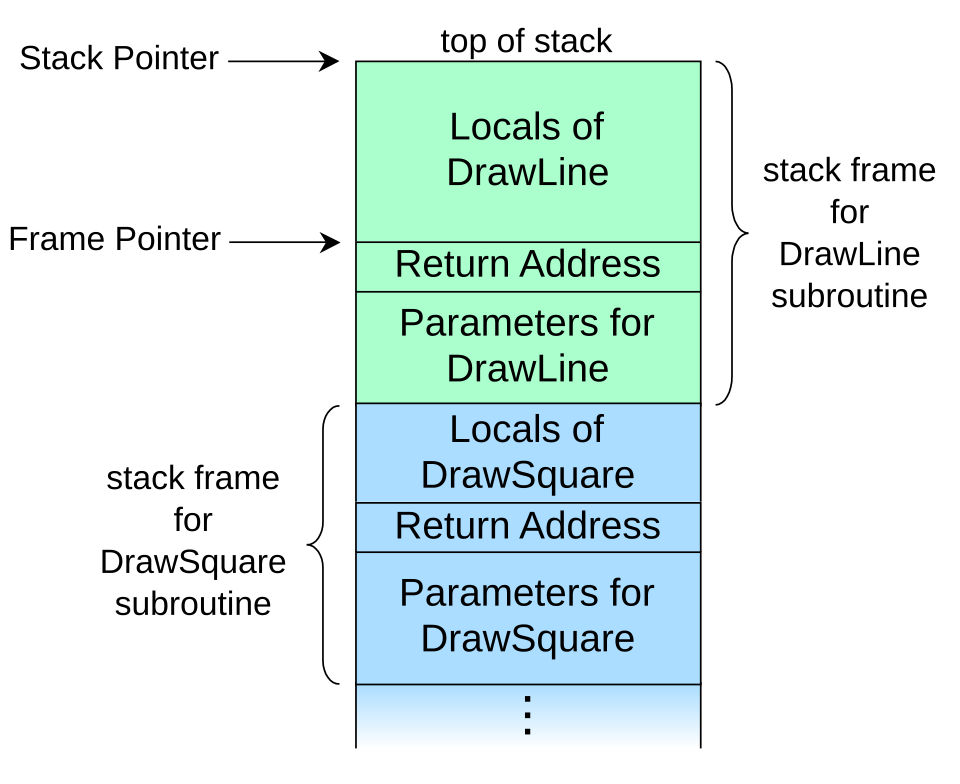
Stack is a region of memory that exists per-thread and serves as the working memory for function execution. When a function is called, space gets carved out on the stack for that function’s local variables, and some bookkeeping information gets stored there too. When the function returns, that space gets reclaimed.
Why does this matter for security? Because one of the things stored on the stack is the return address, the address the cpu should go to after the current function finishes. If you can overwrite that address with something you control, you control where execution goes next. That’s the core of a stack buffer overflow malice. as in C/C++ we start writing our code in main() but main() is not what is actually called first! So kernel calls execve -> _start (asm entry point) -> __libc_start_main (C Runtime Setup) -> _init -> main() -> exit().
Stack grows downward on x86. “grows downward” means that as you push more things onto the stack, the stack pointer (rsp on x64) moves to lower memory addresses. This is counterintuitive but important to internalize early.
What actually lives in a stack frame:
return address : 8 bytes on x64. pushed automatically by the CALL instruction. This is what gets overwritten in a classic stack overflow. If you can put an address you control into this location, the next RET instruction becomes a JMP to wherever you want.
saved rbp : 8 bytes if the function uses a frame pointer (many optimized builds dont bother with this). Less critical as a target but it’s between your buffer and the return address in many layouts, so youll overwrite it on the way.
stack canary : 8 bytes on x64 windows, placed by the compiler between your local variables and the saved registers/return address. Its a random value that gets checked before the function returns. If its been modified, the process dies. This is the main thing standing between an overflow and a return address overwrite on any normally compiled binary.
local variables : This is where your buffers live. char buf[256] is a 256-byte region on the stack. If something writes more than 256 bytes into it without checking, the excess bytes go somewhere they shouldnt.
shadow space : Windows-specific and x64-specific. the windows x64 calling convention requires the CALLER to reserve 32 bytes on the stack before calling any function. Its called shadow space or home space. Its always there, even if the function takes zero arguments, even if nothing gets written to it. Its part of the abi contract and you’ll see it in every stack frame.
Here’s what a realistic stack frame looks like for a function with a char buf[256] local variable, compiled with /GS (stack canary on):
higher addresses
+-------------------------------------------+
| caller's frame |
+-------------------------------------------+ <- RSP + 0x130
| return address (8 bytes) TARGET |
+-------------------------------------------+ <- RSP + 0x128
| saved RBP (8 bytes) |
+-------------------------------------------+ <- RSP + 0x120
| stack canary (8 bytes) in the way |
+-------------------------------------------+ <- RSP + 0x020
|char buf[256] <- STARTS HERE |
+-------------------------------------------+ <- RSP + 0x000
| shadow space (32 bytes) |
+-------------------------------------------+
lower addresses
for a function with char buf[256], compiled with /GS (stack canary on):
| higher addresses | |
| return address ← TARGET | RSP + 0x130 |
| saved RBP | RSP + 0x128 |
| stack canary ← in the way | RSP + 0x120 |
| char buf[256] ← starts here | RSP + 0x020 |
| shadow space (32 bytes) | RSP + 0x000 |
| lower addresses |
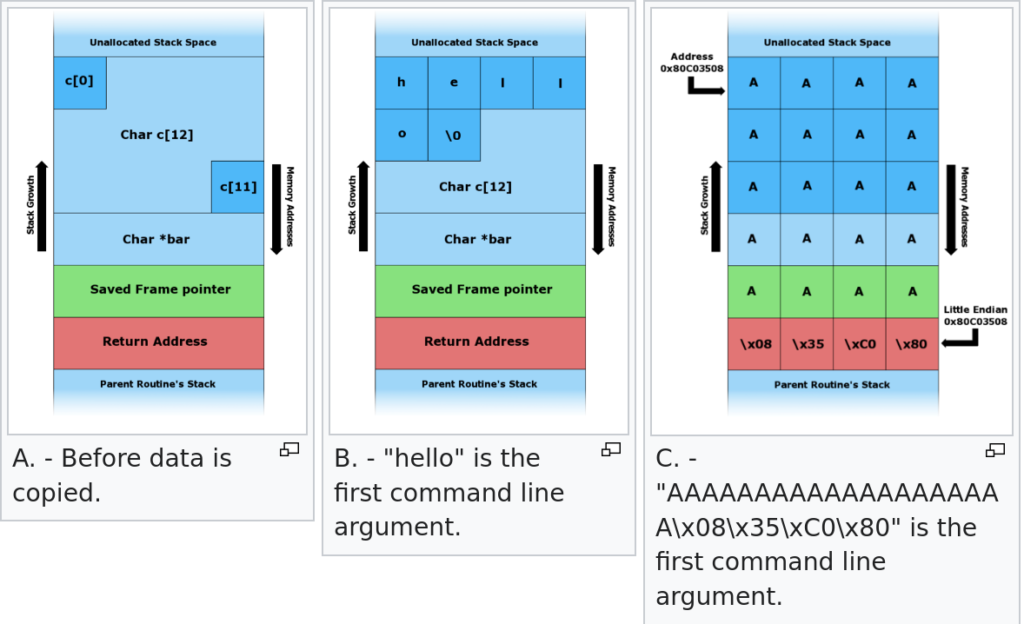
So if we have code taking user input and placing it on stack and there are no enough sanity checks in place, which in a perfect world may be great but not practical. Something like this:
#include <string.h>
void foo(char* bar) {
char c[12];
strcpy(c, bar); // no bounds checking
}
int main(int argc, char* argv[]) {
foo(argv[1]);
return 0;
}
User will easily overflow the buffer and place something else in return address which points to somewhere attacker wants to, that somewhere exactly will be where there would be profit for attacker, hence ‘smashing the stack for fun and profit‘
x86-64 specifics you have to know
On 32-bit x86, the first argument to a function was at the top of the stack. arguments were always passed on the stack. That model is gone on x64 windows.
On x64 windows (the microsoft abi), the first four integer/pointer arguments go in registers: arg1 → rcx, arg2 → rdx, arg3 → r8, arg4 → r9. Only argument 5 and beyond spill to the stack.
Registers you care about most:
rip: instruction pointer. equivalent of eip on 32-bit. this is what you’re ultimately trying to control. its not directly writable — you control it indirectly by overwriting the return address and then executing RET.
rsp: stack pointer. points to the top of the current stack frame. when you build a rop chain, you’re essentially building a fake stack that rsp walks through.
rbp: frame pointer. often not used in optimized code. when its present, its pushed onto the stack at function entry and popped at exit.
rax: return value register. also used as a scratch register in a lot of gadgets.
Canonical addresses: x64 uses 48-bit virtual addressing. bits 63 through 48 have to be copies of bit 47 (sign extension). Any address that doesnt follow this rule is non-canonical. Writing 0x4141414141414141 into the return address gives you a GP fault at the RET instruction, not an access violation at 0x4141… valid user-mode addresses on x64 windows look like 0x00007FF_______.
stack alignment: Windows x64 abi requires rsp to be 16-byte aligned at the point of a CALL. When you’re building rop chains manually, misaligned rsp crashes you at specific instructions (movaps and anything using xmm registers). Fix is usually adding an extra RET gadget to your chain to adjust alignment by 8 bytes.
IV. What to look for
Stack overflows dont appear randomly in code. They cluster around specific operations. When youre doing a code audit, these are the things you follow.
Parse
Anytime code reads structured input and extracts fields, ask: where does the output go, and is the output size bounded by something the attacker controls? Classic pattern: a length-prefixed protocol field. the message format says “next 2 bytes are the length of the following field.” code reads that 2-byte length (max value 65535), then does memcpy(stack_buf, input_data, length). If stack_buf is 512 bytes and length came from the attacker, you see the problem.
Decode
Decoding expands data. base64, url encoding, html entity encoding, custom encodings can all have edge cases where the output is larger than you expected. The one that bites people in practice: character encoding conversion. utf-8 to utf-16 doubles the byte count for ascii input. If you size your output buffer based on the input byte count and then do the conversion, your output buffer is half the size it needs to be.
Convert
Similar to decode but broader. the specific thing to watch: any conversion where the output is potentially larger than the input, and the output goes into a fixed stack buffer sized from the input. MultiByteToWideChar on windows is the classic, size your output based on input byte count and you’ve got a bug.
Deserialize
Take a serialized data structure and reconstruct it in memory. The danger: the serialized format encodes count fields and size fields. If those come from attacker-controlled data and the deserializer uses them to control how much gets written to stack memory, you can overflow.
struct entry items[MAX]; // fixed-size stack array
int count = read_int(data);
for (int i = 0; i < count; i++) {
items[i] = parse_entry(data); // overflow when count > MAX
}
Interpret
Virtual machines, bytecode interpreters, scripting engines. If the interpreter maintains state in fixed-size stack buffers (operand stack, frame table, etc.) and the bytecode can drive the interpreter into using more state than the buffers can hold, overflow.
Compress / Decompress
Decompression is the dangerous direction. Small compressed input can decompress to a very large output. lz-family algorithms (lz4, lzma, lz77, zlib) can have expansion factors of 1000x or more with carefully crafted input. If the decompressed output goes into a stack buffer sized based on any property of the compressed data rather than a hard maximum, you’ve got an overflow waiting.
As said before go checkout ost2 vuln class.
V. Actual Causes
So if you’re glossing over the code and want to smash the stack you should look out for following things:
Unsafe Functions
These are the ones you should grep for in any codebase:
gets(buf): Reads a line from stdin with no size limit. removed from c11 because it literally cannot be used safely. still exists in old code.
strcpy(dst, src): Copies src into dst until it hits a null terminator. no size parameter. if src is longer than dst, it overflows.
strcat(dst, src): Appends src to dst. same problem. the amount written depends on how full dst already is — so even if you checked the length of src against sizeof(dst), if dst is already half-full, you can still overflow.
sprintf(buf, fmt, …): Formats into buf with no size limit. replace with snprintf always.
scanf(“%s”, buf): Reads a whitespace-delimited token with no width limit. use “%255s” or whatever the right width is, never bare “%s”.
memcpy(dst, src, n): has a size parameter, but the bug is when n comes from untrusted input and isnt checked against sizeof(dst) before the call.
recv(sock, buf, bufsize, flags) — bufsize should be sizeof(buf). recv(sock, buf, 4096, 0) when buf is char buf[256] overflows on any input over 256 bytes.
Loops With Attackers Data
this is subtler and easier to miss in a review:
char output[512];
int idx = 0;
while (more_input()) {
output[idx] = next_byte();
idx++; // no check: idx < 512
}Loop advances idx based on how many iterations run. The number of iterations is controlled by the input. If the input has more than 512 bytes, idx goes past the end of output and you’re writing into adjacent stack memory. This pattern shows up in character filtering loops, encoding loops, accumulator patterns.
Off-By-One
char buf[256];
if (len <= 256) { // should be < 256
memcpy(buf, data, len);
buf[len] = '\0'; // writes buf[256] — past the end
}EUREKA: ONE EXTRA BYTE. Some stack layouts that byte corrupts the low byte of a saved pointer or the least significant byte of the stack canary. not always exploitable. Sometimes very exploitable.
NULL TERMINATOR HANDLING
strncpy(buf, src, sizeof(buf))
does NOT null-terminate if src is exactly sizeof(buf) bytes long. any subsequent strlen(buf) walks past the end of buf until it hits a zero somewhere in adjacent memory. strncat is even worse its third parameter is the number of bytes to append, not the total buffer size.
VI. Prevention
Sanitization and Input Validation
The core principle: validate before you use. Check length fields against the actual size of the destination buffer before you do any write. Do this check in the same function where the write happens, not in some caller that might not always run the check.
// bad
void process(char *data, int len) {
char buf[256];
memcpy(buf, data, len); // len could be anything
}
// good
void process(char *data, int len) {
char buf[256];
if (len <= 0 || len >= sizeof(buf)) return;
memcpy(buf, data, len);
}Use sizeof() directly rather than a separate constant, they can drift.
Safe Functions
gets -> fgets(buf, sizeof(buf), stdin)
strcpy -> strcpy_s(dst, sizeof(dst), src) [windows]
-> strlcpy(dst, src, sizeof(dst)) [linux/bsd]
strcat -> strcat_s(dst, sizeof(dst), src)
sprintf -> snprintf(buf, sizeof(buf), fmt, ...) [always]
vsprintf -> vsnprintf(buf, sizeof(buf), fmt, ap)
scanf("%s") -> scanf("%255s") with explicit widthFORTIFY_SOURCE (linux / gcc / clang)
Compile with: -D_FORTIFY_SOURCE=2 -O1
This replaces dangerous library functions with versions that know the destination buffer size. If a call would overflow, the fortified version aborts the process instead of silently corrupting memory. Level 2 adds runtime checks on top of compile-time ones, use this. level 3 (gcc 12+) is more aggressive with dynamic object sizes.
On windows the rough equivalent is /sdl, which adds extra security-related warnings and some runtime checks.
Safer Languages
rust: The borrow checker prevents out-of-bounds array writes at compile time. All indexing is bounds-checked. you cannot have a classic stack buffer overflow in safe rust.
go: Slices carry length and capacity metadata. All slice indexing is bounds-checked at runtime.
C# / Java / Python: Managed runtimes bounds-check all array accesses. Write past the end throws an exception rather than corrupting memory.
the honest tradeoff: C gives you total control and zero overhead. that control is exactly what creates this entire vulnerability class. for network-facing services that parse untrusted input, that tradeoff is usually not worth it.
VII. Detection
Compiler Warnings
Before anything else: enable all warnings and compile clean.
msvc: /W4 /WX /analyze
/W4 = highest warning level
/WX = treat warnings as errors
/analyze = static analysis pass, catches size mismatches
gcc: -Wall -Wextra -Werror -Wformat=2 -Wformat-overflow
-Wformat-overflow: warns on sprintf/snprintf that can overflowThese are free, there is no reason not to have them on.
Static Analysis Tools
codeql: Github’s query-based analysis. You write queries that describe dangerous patterns: “data flows from recv() into memcpy() as the size argument without an intervening bounds check.” free for open source. integrates into ci via github actions. high payoff, real learning curve. For more deep dive check out ToB Handbook.
semgrep: Pattern matching rules, faster to get started than codeql. Good for catching known-bad function calls and simple taint patterns. runs in seconds. use it for “catch the obvious stuff in ci.”. Again ToB.
coverity: Commercial but free tier for open source. very mature, very low false positive rate. best signal-to-noise of the static analysis tools.
flawfinder / rats: Older, basically grep for dangerous function names with some context. Lots of false positives but zero configuration. Useful for an initial sweep.
ghidra / ida pro: When source is unavailable. Find calls to recv/readfile/etc, trace the output buffer forward through the call graph, look for uses of that buffer as a destination in copy operations.
Dynamic Analysis Sanitizers
addresssanitizer (asan): One to know, available in gcc, clang, msvc (/fsanitize=address). Instruments every memory access, maintains shadow memory tracking which bytes are valid. Write past the end of a stack buffer is detected immediately with a full report: type of violation, address accessed, stack trace, memory map. ~2x slowdown, 3x memory. not for production, perfect for fuzzing and test suites.
ubsan: Catches integer overflow, null pointer dereference, misaligned access, array index out of bounds. run alongside asan, they catch different things. -fsanitize=undefined
valgrind: linux only, no recompilation needed. 10-50x slower than native. Less useful than asan for stack overflows specifically but catches heap issues asan sometimes misses.
windows application verifier: Built into the windows sdk, free. enables page heap, guard pages after every allocation. Any overflow immediately faults. No source required.
Fuzzing
Coverage-guided fuzzing + asan is probably the most effective combination for finding stack overflows in practice.
afl++: Standard, simple as that. Instruments the binary with coverage tracking. Generates inputs, mutates toward new coverage, saves crashes. For network targets, write a harness that calls the parsing function directly.
winafl: afl port for windows, uses dynamorio or intel pin. Slower than afl++ on linux but necessary for windows-only targets.
libfuzzer: Integrated into llvm/clang. Write a fuzz target function, compile with -fsanitize=fuzzer,address, run it. Very fast because it runs in process.
boofuzz: Python framework for network protocol fuzzing. Define the protocol structure in code and it systematically mutates fields. Good for length-field overflows in custom binary protocols.
Manual Code Review
Automated tools miss things. logic errors, complex multi-function taint flows, and subtle arithmetic issues require human eyes.
How i approach a manual review looking for stack overflows: find all entry points where external data comes in (recv, read, ReadFile, fread, getenv, GetCommandLine...) and mark every variable that carries that data as tainted. Follow the tainted variables forward, does any tainted value end up as the size argument to a write? Does any tainted value control how many times a loop iterates while writing to a stack buffer? Look specifically at parse, decode, convert, deserialize, interpret, decompress operations. For each write operation: what is the destination? what is sizeof()? Is the write amount bounded before writing begins? is the bound check on the right side (< vs <=)?
Check arithmetic separately: can two length fields be added together to overflow SIZE_MAX? can count * element_size overflow before the buffer check fires? integer overflow feeding into a buffer size check is a common bypass pattern.
VIII. Mitigations
Mitigations are not fixes. The bug is still there. Mitigations are engineering obstacles that make exploitation more expensive and more complex. They work. Modern exploits require chaining multiple techniques specifically because of them.
Stack Canaries (/GS on windows, -fstack-protector on linux)
At function entry, compiler-generated code loads a random value from a global (__security_cookie) and XORs it with the current rsp value. this per frame XOR means every function has a different effective canary, a canary leaked from one function cant be reused in another. At function exit, before RET, the canary is recomputed and compared. mismatch → __report_gsfailure → process terminates.
What it stops: sequential overflows from a stack buffer to the return address. You have to go through the canary to reach the return address, and modifying the canary triggers termination.
What it doesnt stop: non-sequential writes (arbitrary write primitive skips the canary entirely), information leaks (if another bug leaks the canary value, include it unchanged in your payload), exception-based bypasses (exception handler triggered before epilogue canary check runs).
ASLR (address space layout randomization)
Randomizes where things get loaded in memory every time the process starts. The binary’s base address, dll bases, heap start, stack start — all random. on x64 windows: ~17 bits of entropy for image bases. with 17 bits thats 131072 possible locations, brute force is not practical.
What it stops: hardcoded addresses in exploits. if you cant know where ntdll.dll loads, you cant hardcode the address of a VirtualProtect gadget.
What it doesn’t stop: information leaks. if any bug lets you read a pointer value pointing into a loaded module, you can compute the module’s base address. modules compiled without /DYNAMICBASE load at fixed addresses every time, if any such module is loaded in the target process, its gadgets are always at known addresses.
DEP / NX (data execution prevention)
CPU’s nx bit marks pages as either executable or data, not both. stack pages and heap pages are data, not executable. If execution reaches a non-executable page, the cpu raises a fault.
What it stops: direct shellcode injection. put shellcode on the stack and jump to it, fails because the stack is not executable.
What it doesn’t stop: return-oriented programming (ROP). ROP doesnt inject new code. it chains together short sequences of existing instructions (gadgets) that end in RET. all the gadgets are in executable memory, dep never fires. calling VirtualProtect via ROP to mark a region executable, then jumping to shellcode — dep is bypassed by making the shellcode’s page executable before jumping.
CFI / CFG (control flow integrity / control flow guard)
Restricts where indirect calls and jumps can go. Windows CFG maintains a bitmap of valid indirect call targets, essentially all function entry points. Every indirect call (call [rax], call [rbx+offset]) is preceded by a check against this bitmap. If the target isnt a valid function entry point, the process terminates. compile with: /guard:cf (default in modern visual studio).
what it stops: rop chains calling through invalid intermediate addresses. overwrites of function pointers to arbitrary locations.
what it doesnt stop: return addresses. RET is not checked by CFG. a stack overflow that overwrites the return address and returns to a valid function entry point (VirtualProtect, WriteProcessMemory) is completely unaffected. valid CFG targets used as trampolines — some legit entry points can be called with crafted arguments to pivot execution further.
CET / shadow stack
Hardware feature on intel 11th gen+ and amd zen 3+. Shadow stack is a separate, cpu-protected copy of return addresses. Every CALL pushes the return address to both the regular stack AND the shadow stack. The shadow stack is not writable by normal memory operations.
On every RET, the cpu compares the return address popped from the regular stack against the copy in the shadow stack. If they dont match, the cpu raises a #CP (control protection) fault.
Stack overflow that overwrites the return address on the regular stack will be caught immediately when the next RET fires, the regular stack copy and the shadow stack copy disagree.
Bypassing CET requires either a kernel-level bug, or finding a code path where the corrupted return address somehow gets written to the shadow stack as well (setjmp/longjmp edge cases, certain JIT-related patterns). this is why modern full-chain browser exploits on up-to-date windows require a kernel component.
Mitigation Stack in Practice
On a fully patched windows 11 system with a modern application, to exploit a stack overflow you need: an info leak to bypass aslr, a technique to bypass or leak the canary, a rop chain that uses only valid cfg targets, and either a second bug to bypass cet or a rop chain that avoids RET-based control flow (which is nearly impossible for anything useful).
This is why fully-weaponized exploits against modern systems are rare, expensive, and usually involve chaining two or three separate vulnerabilities.
IX. All this for what?
This was the foundation. stack overflows are the entry point because they demonstrate the core concepts clearly: memory layout, control flow hijacking, the role of mitigations as obstacles rather than solutions.
SEH overwrites: On 32-bit windows, the structured exception handler chain lived on the stack. corrupting it gave a different execution path that historically bypassed stack canaries. on x64 windows, SEH is table-based rather than stack-based, which changes the technique entirely.
Heap exploitation: The heap has completely different allocation mechanics (windows uses the segment heap). use-after-free, heap overflow, and double-free bugs require understanding the allocator internals. More complex than stack overflows but extremely common in modern CVEs.
Format String bugs: printf(user_string) where user_string is attacker-controlled. %n writes to memory. %p/%x leak stack contents. A single format string bug can give you arbitrary read and arbitrary write.
Integer Overflow as an enabler: A size calculation that overflows (count * sizeof(item) wraps around) leads to an undersized allocation that gets overflowed by the actual data. this is how many real heap overflow CVEs work.
Kernel exploitation: Everything above applies in ring 0, plus you get to bypass process isolation entirely if it works. different debugging setup, patchguard, hvci on modern systems. the techniques overlap.
0-day Research Methodology: Applying the detection techniques systematically to code that hasnt been publicly analyzed. fuzzing at scale, variant analysis on vendor patches, targeted manual review of high-value code paths. this is where all the foundational knowledge eventually points.
ALERT ALERT ALERT
one thing i want to address before wrapping up, its easy to look at all these mitigations and think stack buffer overflows are basically dead. and for the most part, on a fully patched windows 11 machine running modern software or some highly verified library, yeah, theyre not going to get you very far on their own. but that picture changes a lot depending on what youre looking at. firmware, embedded systems, iot devices. a lot of that stuff runs without canaries, without aslr, without dep, either because the hardware doesnt support it or nobody bothered to enable it. in those environments the "classic" overflow is still very much a real technique, not just a ctf artifact.
and even when on a target with full mitigations, finding a linear buffer overflow isnt the end of the road. maybe it doesnt give you code execution directly. but it can still corrupt adjacent stack variables, cause an out-of-bounds write somewhere useful, or leak a pointer that lets you break aslr. overflows feed into other primitives(which are way more powerful and featureful for the attacker). so even when something looks unexploitable on the surface its worth understanding what the bug actually gives you before writing it off.
Hope to continue this series ahead and cover more topics on vulnerabilties, later on exploitation techniques … and then real world CVE writeups.
Leave a Reply